Sentiment analysis as a field has come a long way since it was first introduced as a task nearly 20 years ago. It has widespread commercial applications in various domains like marketing, risk management, market research, and politics, to name a few. Given its saturation in specific subtasks — such as sentiment polarity classification — and datasets, there is an underlying perception that this field has reached its maturity.
Interested to know our take on the current challenges and future directions of this field using the following papers as compass?
If you find this repository useful in your research, you may cite the paper below where we briefly cover the progress in sentiment analysis and further address the key challenges and new directions in this domain.
Have you ever received a text from a family member and couldn’t tell if they were joking or not? Unless we directly tell the person how we feel, emotions and tone don’t carry well over text, which often makes it difficult to determine the intent of a message. We can use punctuation to help, but there’s no universal way to communicate things like sarcasm or irony through text.
In 1580, English printer, Henry Denham, tried to solve this problem by coming up with this mark to symbolize sarcasm: ⸮
Spoiler alert, it never quite caught on and when technology like text messages, live chat, and social media came me about, people still had no definitive way of identifying the sentiment behind a text message. This became a real problem for businesses as they realized how difficult it was to determine if customer feedback was positive or negative. It’s hard for a customer to describe a problem when they only can use 280 characters, and without proper context, customer service teams don’t have the information they need to appropriately respond to the issue.
As text-based communication like social media and live chat become more popular in customer service, businesses need a way to accurately and efficiently filter their customers’ feedback. This is where a sentiment analysis tool comes in handy to interpret a text and explain the intent or tone of a customer’s message.
In this post, we’ll explain what a sentiment analysis tool is and provide a list of the best options available for your team this year.
What Is a Sentiment Analysis Tool?
A sentiment analysis tool is software that analyzes text conversations and evaluates the tone, intent, and emotion behind each message. By digging deeper into these elements, the tool uncovers more context from your conversations and helps your customer service team accurately analyze feedback. This is particularly useful for brands that actively engage with their customers on social media, live chat, and email where it can be difficult to determine the sentiment behind a message.
Brand Sentiment Analysis
Sentiment analysis helps brands learn more about customer perception using qualitative feedback. By leveraging an automated system to analyze text-based conversations, businesses can discover how customers genuinely feel about their products, services, marketing campaigns, and more.
Benefits of Adopting a Sentiment Analysis Tool
If your company provides an omni-channel experience, a sentiment analysis tool can save your team valuable time organizing and reporting customer feedback.
Rather than going through each tweet and comment one-by-one, a sentiment analysis tool processes your feedback and automatically interprets whether it’s positive, negative, or neutral. Then, it compounds your data and displays it in charts or graphs that clearly outline trends in your customer feedback. This not only gives your team accurate information to work with, but frees up time for your employees to work on other tasks in their day-to-day workflow.
Now that you know what a sentiment analysis tool is and how it can benefit your business, let’s take a look at some of the best tools available for 2021.
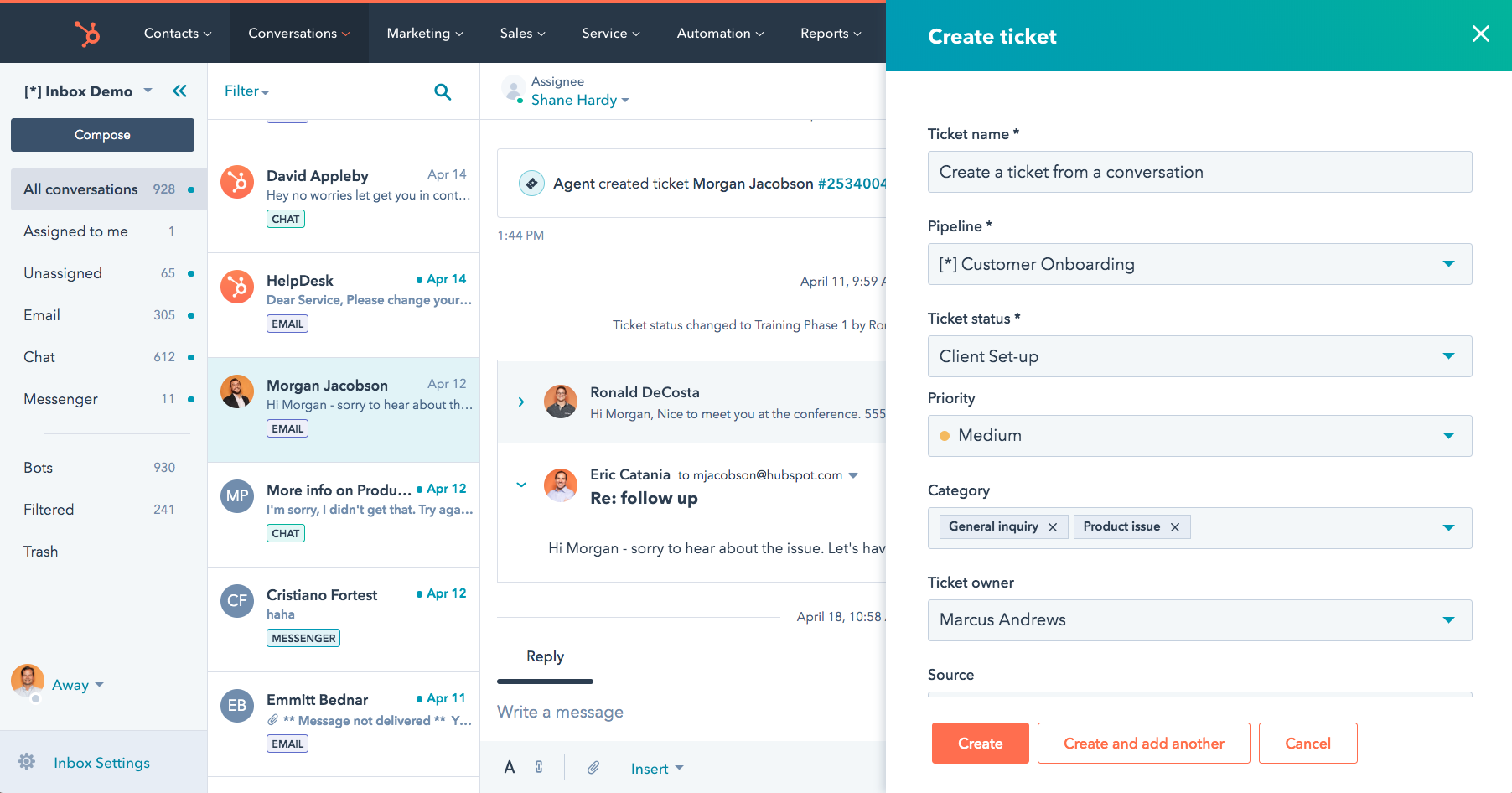
HubSpot’s Service Hub tools include a customer feedback tool that can break down qualitative survey responses and evaluate them for positive or negative intent. It uses NPS® surveys to clarify whether a customer’s review was good or bad and organizes them based on their sentiment. Users analyze the results by looking at one comprehensive dashboard that includes charts and graphs which provide an overview of customer satisfaction.
HubSpot’s Service Hub suite can also analyze customers on an individual basis. You can integrate your CRM with Service Hub and review survey responses from specific contacts in your database. That way, your team can quickly identify customers who are unhappy and follow up with them after they’ve had a negative experience with your brand. Remember, 58% of customers will stop doing business with you if your company falls short of their expectations. this gives your team an opportunity to intercept unhappy customers and prevent potential churn.
Talkwalker’s “Quick Search” is a sentiment analysis tool that’s part of a larger customer service platform. This tool works best with your social media channels because it can tell you exactly how people feel about your company’s social media accounts. Quick Search looks at your mentions, comments, engagements, and other data to provide your team with an extensive breakdown of how customers are responding to your social media activity. This helps your team plan and produce effective campaigns that captivate your target audience.
Repustate has a sophisticated text-analysis API that accurately assesses the sentiment behind customer responses. Its software can pick up on short-form text and slang like lol, rofl, and smh. It also analyzes emojis and determines their intention within the context of a message. For example, if I use a 😉 emoji, Repustate tells you if that’s a positive or negative symbol based on what it finds in the rest of the conversation.
Repustate also lets you customize your API’s rules to have it filter for language that may be specific to your industry. If there’s slang or alternate meanings for words, you can program those subtleties into Repustate’s system. This way you have full control over how the software analyzes your customers’ feedback.
Lexalytics offers a text-analysis tool that’s focused on explaining why a customer is responding to your business in a certain way. It uses natural language processing to parse the text, then runs a sentiment analysis to determine the intent behind the customer’s message. Finally, Lexalytics concludes the process by compiling the information it derives into an easy-to-read and shareable display. While most sentiment analysis tools tell you how customers feel, Lexalytics differentiates itself by telling you why customers feel the way that they do.
Critical Mention is different than the other options on this list because it analyzes news and other publications that reference your business. This way, you can see the sentiment behind stories that are rapidly surfacing to the public. Since news coverage is now a 24/7 affair, it helps to have software that can monitor the internet and alert you to any buzz your business is making.
Critical Mention can even alert you to stories that appear on television. You can search through video files for mentions of your company and easily clip videos to share with other employees. If your business gets positively mentioned on a live broadcast, quickly access the video segment and share it on your social media channels. This can help you create effective online content that capitalizes on timely marketing opportunities.
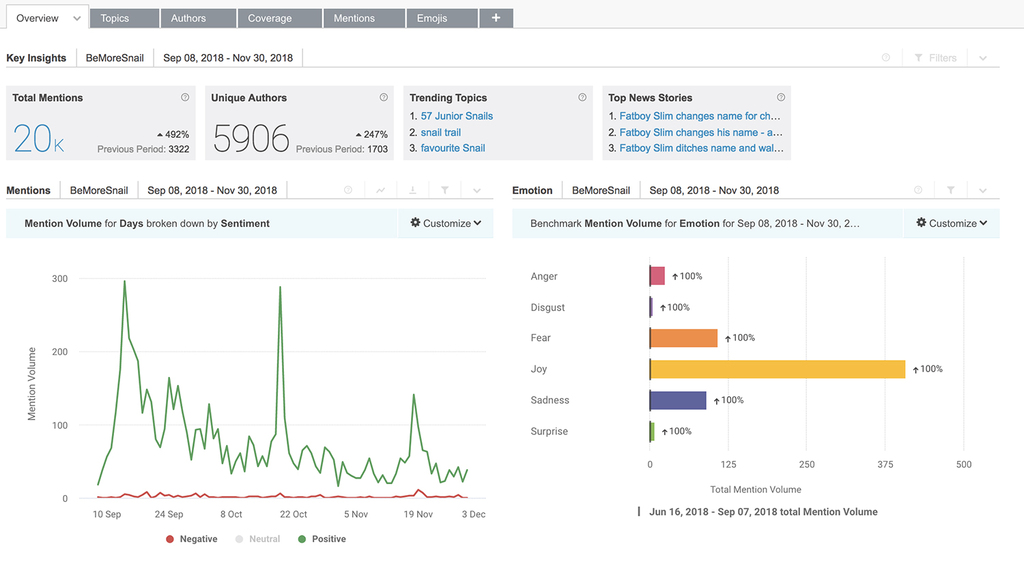
One of the coolest features that Brandwatch provides is its “image insights” tool which can identify images associated with your brand. For example, say you upload an image of your brand’s logo. Brandwatch surfs the web for images that include that logo. Then, it compiles the images into a list and highlights exactly where your brand’s logo is appearing.
Additionally, Brandwatch’s software provides interesting insights into each image it finds. This includes metrics like mention volume, aggregate followers, and latest activity. With Brandwatch, your team sees where your brand’s images are appearing and how those images are performing with your target audience.
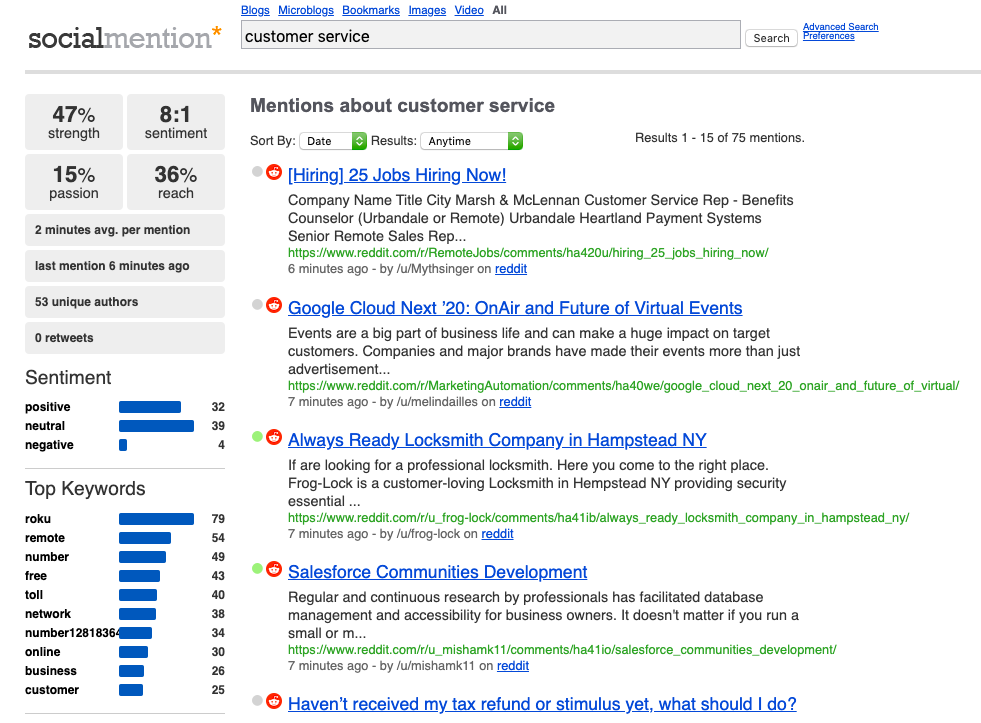
Social Mention is a free social media analysis tool that provides users with one of the best bangs for their buck. First, users don’t have to create an account or download software. Instead, you just need to navigate to their site and search for your keyword like you would with any search engine. Upon entering your search, Social Mention pulls data about your keyword from every social media site and compiles it into a comprehensive summary.
This summary isn’t primitive, either. It can tell you useful things like the ratio of people speaking positively about your keyword versus those who are speaking of it negatively. It can also tell you what percentage of people are likely to continue mentioning your keyword and how popular your brand is on social media. While you can’t really analyze individual pieces of data, Social Mention is a great option for people looking to get a brief synopsis of their social media reputation.
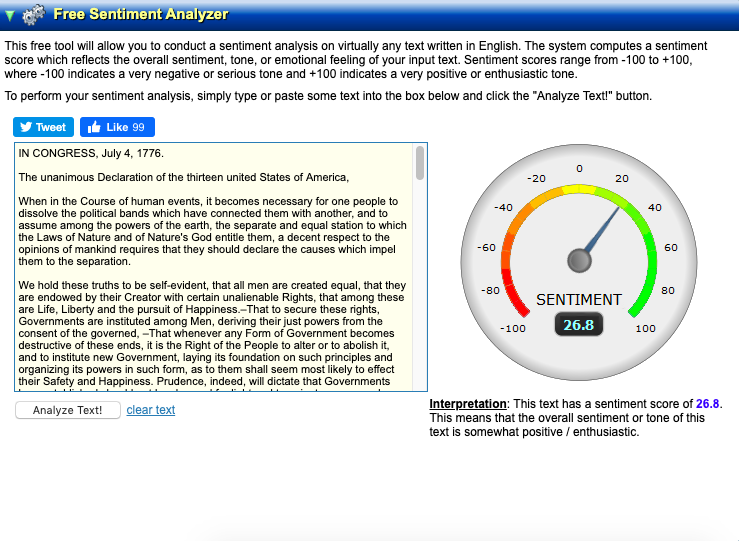
Working with Sentiment Analyzer is a breeze. Simply navigate to their site, copy the text you want to analyze, and paste the text into the box. Select “Analyze!” and the website will evaluate your text and give you a “sentiment score.”
While that might sound like magic, Sentiment Analyzer uses “computational linguistics and text mining” to determine the sentiment behind your piece of text. It then compounds and compares its findings to produce an overall score. This makes it a great tool for companies looking to quickly decipher the intent behind a confusing response from a customer.
MAXG is a HubSpot integration that analyzes customer data found in your CRM. It uses industry benchmarks to compare your company’s information against others in your marketplace, so you know how your business is performing compared to your competitors.
MAXG can analyze a wide range of quantitative and qualitative data, including CTA’s, blog posts, and emails. And, with its insightful recommendations tool, it won’t just provide you with a clear look at how customers are interpreting your content, but it’ll also make suggestions for how you can improve engagement.
Social Searcher is a social media monitoring platform that includes a free sentiment analysis tool. All you have to do is search for a keyword, hashtag, or username, and Social Searcher will tell you whether or not the buzz surrounding this topic is positive or negative. It also breaks reports down by social media platforms, so you can see exactly how your brand is performing across different apps and channels.
Rosette is great for international businesses because it can review text-based data in over 30 different languages. This means you won’t have to translate conversations before you upload them, which is not only faster but ensures greater accuracy. Since most customers will use shorthand or slang, third-party translation tools can inadvertently change the meaning of their text. With Rosette, it’s system is built to analyze text in the language that it’s written, so you won’t lose any valuable feedback even if it’s written informally.
MonkeyLearn is a sentiment analysis tool that’s easy to customize. All you have to do is create categorization tags then manually highlight different parts of the text to show what content belongs to each tag. Over time, the software learns on its own and can process multiple files simultaneously.
MonkeyLearn also provides its customers with a free “Word Cloud” tool that tells them what words are used most frequently within each categorization tag. This can help businesses discover common customer roadblocks by looking for repeat mentions of specific products or services. If you notice one product is consistently listed under a negative categorization tag, this would suggest there’s an issue with that product that customers are unhappy about.
Tired of interpreting your customers’ responses in the first place? Learn how to get better feedback by reading these tips for improving your customer feedback survey.
Net Promoter, Net Promoter System, Net Promoter Score, NPS and the NPS-related emoticons are registered trademarks of Bain & Company, Inc., Fred Reichheld and Satmetrix Systems, Inc.
Since the release of Kinect, there have been many efforts from Microsoft, as well as, various other open source projects to track human motion. Many frameworks exist which give the developer an abstraction from tracking human movement and instead, provide them with parameters such as hand gestures. We aim to take it a step further. Using such frameworks, we analyzed hand and leg movements, combined with whole body’s motion to get a score of user’s emotions. Using the result of this analysis we developed a framework which other developers can use. While using this framework, they not only have hand and body movement data, but also the emotions of users which they can utilize in their applications. Applications can include creation of music and arts for the sake of advertisement, interactive installations and games which either use emotions as an input event or for studying emotional changes as a reaction to a certain event.
The second part of the project focuses on developing an application which demonstrates the full potential of this framework. We created a desktop application which will create real-time music and art based on the user performing intentionally or randomly. The music scale and saturation of the colors used is based upon the emotions of the performer.
Setup
OpenNI
Installing OpenNI and Kinect Driver on Windows 7 (x86)
Select PrimeSense Package Stable Build for Windows x86 Development Edition
While installing, select OpenNI and NITE middleware. DO NOT check PrimeSense hardware as that driver is not for Microsoft Kinect
Download Kinect driver from Kinect (make sure that neither Microsoft’s nor any other driver for Kinect is installed on your computer) and install it.
To run the samples included with NITE, copy all .xml files from “[PrimeSense root directory]/NITE/Data” to “[PrimeSense root directory]/SensorKinect/Data”
Configuring OpenNI Development in Visual Studio 2010
Create a new or open an existing Visual Studio 2010 project
Open project properties
Go to C/C++ -> General -> Additional Include Directories and add “[OpenNI root directory]/Include”
Go to Linker -> General -> Additional Library Directories and add “[OpenNI root directory]/Lib”
Go to Linker -> Input -> Additional Dependencies and add OpenNI.lib
Your code should include XnOpenNI.h if you are using C interface, or XnCppWrapper.h if you are using C++ interface
Optionally, you can use the namespace “xn” or you can reference objects using scope operator (For example, “xn::Context context”)
Configuring OpenNI Development in Visual Studio 2012
Installation and configuration in Visual Studio 2012 is exactly the same as Visual Studio 2010. But OpenNI doesn’t let you use their library in compiler version greater than VS 2010. But it can be overridden using the following steps:
Within the OpenNI libraries directory, locate the file XnPlatform.h
At the top of the file you will find the code “if defined(_WIN32). Beneath this you will find another condition which checks the compiler version
Comment out that piece of code and you will be able to compile the project
Configuring OpenNI Development in Java IDE’s
Create a new project in Eclipse or Netbeans
Add “[OpenNI root directory]/Bin/org.OpenNI.jar” and “[NITE root directory]/Bin/com.primesense.NITE.jar” to “additional libraries
Technologies Used:
Microsoft Windows 7 (x86)
PrimeSense’s SensorKinect driver for Kinect
NITE middleware for OpenNI
OpenNI
Introduction
Human beings are the most complex living organisms. Despite belonging to the mammals group, they are capable of evolving on such a fast scale and are able to redefine the aspects of their life through various means. Over the decades, human motions have shown such diversity that many scientists are trying to analyze and manipulate this knowledge to provide some benefit to the human race. In this regard, there are researches and attempts to read patterns in human motions and to use them to generate something useful such as art. This is a very promising avenue and can open doorways to more research and development.
Goals
Goal of this project is to:
Develop a framework that gathers mood and motion data. It means that our module will:
Capture human motion
Carry out emotional analysis on motion
And present the results in a well-formed, consistent manner so that it’s a breeze to use the module
Write a demo application that shows full potential of this framework
Literature Review
Human Motion Analysis
Recognition and Re-synthesis of Human Motion with Personalized Variations
The purpose of this research paper was to analyze and recognize various human motions such as walking, jumping etc. It uses Hidden Markov Model recognize motion. This method was successful at recognizing different motions from a scene as well recognizing gender and mood of the actor with 100% accuracy.
In this research paper human motion data was gathered by infrared sensors placed at strategic locations on a human body but I chose to not write the details of the data gathering process as we are using Kinect and we will already have human motion data in the form of joints.
This paper also addressed the problem of transforming one type of motion into another. They used two different approaches to implement this and both were successful in transforming a male walk into a female walk.
3D Human Action Recognition and Style Transformation Using Resilient Back propagation Neural Networks
This paper was published by the same authors as above but it uses Resilient Back propagation Neural Networks instead of Hidden Markov Model to implement the same principles as above.
Conclusion
I have read, at a very abstract level both HMM and neural networks but both are fairly complex so a comparison at this time is not possible. I think we can decide on the algorithm to be used in the implementation phase after we know the exact form in which we have the data that is to be analyzed.
As far as re-synthesis is concerned, I don’t think we need re-synthesis as mentioned in both of these research papers. We are to create totally different form of artifacts from our motion analysis but gathering mood and gender can come in very handy.
Color Detection and Optimization
Aethetic Coloring for Complex Layout Using Genetic Algorithm
Various research papers focused on generating a final color palette which an artist uses to choose a color from. But this paper solved the problem of generating an optimized color scheme based on a certain input colors. This paper relies on Moon (G.D. Birkhoff. Aesthetic Measure. Harvard University Press, Cambridge, MA, USA, 1933) and Spencer (P. Moo n, D.E. Spencer. Aesthetic measure applied to color harmony. Journal of the Optical Society of America, vol. 34, Apr. 1944, pp. 234-242.) color harmony model which is based on psychological experiments. They argue that Genetic Algorithms the best method to solve this kind of problem.
In 1928, Birkhoff formalized the notion of beauty by the introduction of the aesthetic measure, defined as the ratio between order and complexity. Based on this measure Moon and Spencer proposed a quantitative model of color harmony, using color difference and area factor based on psychological factors.
Implementation is carried out using three phases. In the first phase image they read and evaluate the color image and initialize genetic algorithm parameters. The program reads the size of image, number of color and color pairs and area of each color (read in pixels). Genetic algorithm parameters for this phase include string size, number of generations, population size, mutation and crossover rate.
In the second phase evaluation of the aesthetic score for each possible solution takes place. This determines the possibility of survival and reproduction of each solution in the following generations.
Phase 3 is population generation. For each generation, three ages of population (parent, child and combined) are created. The best solutions in this combined population regardless of their origin are retained and passed to the following generation as a parent population.
In the experiment conducted, it took them 55 seconds to read an image and search for 6 unique optimized solutions.
Conclusion
There are also basic rules available to create color combinations. For example, if we hard code a certain color palette into out program and round-off each color read in the frame to one of those found in the color palette. This can be easily done in real time. While the solution mentioned in the research paper above is optimum, I think we are going to have a problem implementing that solution in real time.
Psychological Analysis of Human Motion
Affective States
Affect is described as feeling or emotion. Affective states refer to the different states of feelings or emotions.
Difference between Emotion and Mood
Emotion and mood both are types of affective states but emotion is focused whereas mood is unfocused or diffused.
Arousal, Valence and Stance
Arousal is defined as the level of energy a person possesses while displaying a certain emotion. Valence describes how positive or negative the stimuli is (which is causing a certain emotion in a person). Stance describes how approachable the stimuli are.
Together, these three terms form a model of quantitative analysis of emotion depicted by body language.
Gesture
It is a movement of body that contains information.
GEMEP
The Geneva Multimodal Emotion Portrayals (GEMEP[1]) is a collection of audio and video recordings featuring 10 actors portraying 18 affective states, with different verbal contents and different modes of expression. It was created in Geneva by Klaus Scherer and Tanja Bänziger, in the framework of a project funded by the Swiss National Science Foundation (FNRS 101411-100367) and with support of the European Network of Excellence “Humaine” (IST-2002-2.3.1.6 Multimodal Interfaces, Contract no. 507422). Rating studies and objective behavioral analyses are also currently funded by Project 2 and the Methods module of the Swiss Affective Science Center Grant (FNRS).
Importance of Body Language Analysis
There has been thorough research on motion analysis from facial recognition. But there has been little or no research on body language analysis. It is known that body expressions are as powerful as facial recognition when it comes to emotion analysis. In any social interactions, body language along with facial features communicates the mood/emotions of the person.
In chronic pain rehabilitation, specific movements and postural patterns inform about the emotional conflict experienced by the patients (called “guarding behavior”) which affects their level of ability to relax. If doctors have a way to know that a person’s emotional state is not letting him/her progress in his therapy, then they can formulate ways to treat such patients better.
Students lost motivation when high levels of affective states such as frustration, anxiety or fear are experienced. If such systems are developed which can read the body language of all students present in a class, it can point out when the teacher needs to change his/her tactics.
Survey
The whole point of this research is to answer two questions:
What bodily information is necessary for recognizing the emotional state of a person
Whether specific features of the body can be identified which contribute to specific emotions in a person
1The Role of Spatial and Temporal Information in Biological Motion Perception.pdf
In the experiment conducted, 9 human walkers were fitted with point-lights on all major joints. There movements, both to the left and right, were recorded. From the movements, 100 static images were extracted based on the following four configurations:
Normal spatial and temporal
Scrambled spatial and normal temporal
Normal spatial and scrambled temporal
Scrambled spatial and temporal
The experiment was conducted by both, an algorithm and a human subject in two further stages. Stage 1 analyzed the spatial structure of the frame by matching with some templates of body shapes. Stage 2 analyzed the temporal arrangement. The task was to find the facing direction (form) of the point-light body and movement (motion) direction of the body.
The results show that form can be recognized when temporal data is scrambled and spatial data is intact. But movement cannot be analyzed when either of the data is scrambled.
Evidence for Distinct Contributions of Form and Motion Information to the Recognition of Emotions from Body Gestures.pdf
The research concluded that motion signals alone are sufficient for recognizing basic emotions.
Visual Perception of Expressiveness in Musician’s Body Movements.pdf
Recognizing emotional intentions of a musician by their body movements. The results indicate that:
Happiness, sadness and anger are well communicated but fear was not
Anger is indicated by large, fairly fast and jerky movement
Sadness by fluid and slow movements
But expressions of the same motion varied greatly depending upon the instrument played
Automated Analysis of Body Movement in Emotionally Expressive Piano Performances.pdf
While playing piano, movement is related to both the musical score that is being played as well as emotional intention conveyed. In the experiment conducted the pianist was asked to play the same musical score with different emotional intentions. Two motion cues were studied using an automated system:
Quantity of motion of the upper body
Velocity of head movement
The paper states that a comprehensive account of emotional communication should consider the entire path from sender to receiver. On the sender side, emotions are expressed with appearance and behavior by means of cues which can be objectively measured. On the receiver side, these cues are processed based upon the perception of the receiver. Receiver’s perception can be affected by many things such as culture and his own mood. So, although emotions perceived by the receiver are based on emotions expressed by the sender, but they are not necessarily equal.
This implies that a comprehensive account of emotion communication requires the conclusion of both expression and perception.
There are some distinctive patterns of movements and postural behavior associated with some of the emotions studied:
Lifting shoulders seemed to be typical for joy and anger
Moving shoulders forward is typical for disgust, despair and fear
Survey of various research papers concluded that head movement plays an important role in communication, as well as, perception of emotion.
For dance performances,
Overall duration of time
Contraction index
Quantity of motion
Motion fluency,
showed differences in four emotions: anger, fear, grief and joy. Another research indicated that quantity of motion and contraction index of upper body played a major role in discriminating between different emotions.
Conclusions:
No other emotion, except for sad had any impact on quantity of motion (but this is because of lack of movement space due to piano)
Another research indicates that quantitative analysis of body expressions was also possible. For example, it was concluded that arm was raised 17 degrees higher for angry movements than other emotions and expanded limbs and torso both signify content and joy.
Toward a Minimal Representation of Affective Gestures.pdf
12 emotions expressed by 10 actors
Visual tracking of trajectories of head and hands were performed from frontal and lateral view
Postural and dynamic expressive gesture features were identified and analyzed
Features tracked:
Overall amount of motion captured
The degree of contraction and expansion of body computed using its bounded regions
Motion fluency computed on the bases of the changes magnitude of the overall amount of motion over time
Framework Used for Gesture Representation
Module 1 computes low-level motion features i.e., the 3D positions and kinematics of head and hands
Module 2 computes a vector of higher-level expressive gesture features, including the following five sets of features:
Energy (passive vs. animated)
Spatial extent (expanded vs. contracted)
Smoothness and continuity of movement (gradual vs. jerky)
Forward-backward leaning of the head
Spatial symmetry and asymmetry of the hands with respect to the horizontal and vertical axis
Module 3 reduces the dimensionality of the data, while highlighting the salient patterns in the data set
The paper also contains the details of how each of the features was computed as well as the Dimension Reduction Model.
Suggest that use of upper body only would be sufficient for classifying a large amount of effective behavior.
Kinect
This portion of the document describes Kinect hardware and various software frameworks to be used with Kinect. Microsoft has a well-documented Kinect SDK (for windows only) but some third-party SDK’s and drivers, as well as frameworks are also available. I propose that we use OpenNI coupled with NITE (both are explained below) instead of Microsoft’s SDK as they are open source (you need to purchase a license to use Microsoft’s Kinect SDK for commercial purposes) and can be easily ported to Mac and Linux.
Kinect Sensor Hardware
The Kinect sensor includes:
RGB camera
Depth sensor
Multi-array microphones
Tilt motor
Three-axis accelerometer
The Kinect’s depth sensor consists of an infrared light source , a laser that projects a pattern of dots, that are read back by a monochrome CMOS IR sensor. The sensor detects reflected segments of the dot pattern and converts their intensities into distances. The resolution of the depth dimension (z-axis) is about one centimeter while spatial resolution (x- and y-axes) is in millimeters. Each frame generated by the depth sensor is at VGA resolution (640 x 480 pixels), containing 11-bit depth values which provides 2,048 levels of sensitivity. The output stream runs at a frame rate of 30 Hz.
The RGB video stream also utilizes VGA resolution and a 30 Hz frame rate.
The audio array consists of four microphones, with each channel processing 16-bit audio at a sampling rate of 16 KHz. The hardware includes ambient noise suppression.
Microsoft suggests that you allow about 6 feet of empty space between you and the sensor otherwise you can confuse the sensor.
Kinect Development Software
There are four main Kinect development libraries:
OpenKinect’s libfreenect
CLNUI
OpenNI
Microsoft’s Kinect for Windows
OpenKinect’s libfreenect
Libfreenect is derived from a reverse-engineered Kinect driver and works across all OS platforms. OpenKinect Analysis library communicates with the OpenKinect API and analyzes the raw information into more useful abstractions. They aim to to implement the following features but most of them have not been implemented yet:
hand tracking
skeleton tracking
other depth processing
3D audio isolation coning?
audio cancellation (perhaps a driver feature?)
Point cloud generation
Inertial movement tracking with the built in accelerometer or an attached WiiMote
3d reconstruction
GPU acceleration for any of the above
CLNUI
CLNUI is aimed for windows only but allows multiple kinects to work together.
OpenNI (Open Natural Interaction)
OpenNI is a software framework and an API and provides support for:
Voice and voice command recognition
Hand gestures
Body Motion Tracking
OpenNI is a multi-language, cross-platform framework that defines API’s for writing applications utilizing Natural Interaction. The main advantage of this framework is that you write software independent of the hardware. So, for example, we can aim to write a Human Motion Analysis program which can analyze human motion using kinect if it is available or the same program would use a camera if Kinect is not available.
Sensor modules that are currently supported are:
3D sensor
RGB camera
IR camera
A microphone or an array of microphones
Middleware components that are supported are:
Full body analysis middleware: a software component that processes sensory data and generates body related information (typically data structure that describes joints, orientation, center of mass, and so on)
Hand point analysis middeware: a software component that processes sensory data and generates the location of a hand point
Gesture detection middleware: a software component that identifies predefined gestures (for example, a waving hand) and alerts the application
Scene analyzer middleware: a software component that analyzes the image of the scene in order to produce such information as:
The seperation between the foreground of the scene and the background
The coordination of the floor plane
The individual identification of figures in the scene (and output its current location and orientation of joints of this figure)
NITE
An important reason for using OpenNI is its support for middleware. The NITE library understands the different hand movements as gesture types based on how hand points change over time. NITE gestures include:
Pushing
Swiping
Holding steady
Waving
Hand circling
Primesense’s NITE middleware allows computers or digital devices to perceive the world in 3D. NITE comprehends your movements and interactions within its view, translates them into application inputs, and responds to them without any wearable input.”
Including computer vision algorithms, NITE identifies users and tracks their movements, and provides the framework API for implementing Natural-Interaction UI controls based on gestures. NITE can detect when you want to control things with only hand gestures, or when to get your whole body involved.
Hand control: allows you to control digital devices with your bare hands and as long as you’re in control, NITE ignores what others are doing.
Full body control: lets you have a total immersive, full body video game experience. NITE middleware supports multiple users, and is designed for all types of action.
Comparison between Microsoft’s SDK and OpenNI
Microsoft’s Kinect SDK covers much the same ground as OpenNI. The low-level API gives access to the depth sensor, image sensor, and microphone array, while higher-level features include skeletal tracking, audio processing, and integration with the Windows speech recognition API.
The main area where SDK wins over OpenNI is audio. Other pluses for Microsoft’s Kinect SDK are its extensive documentation and ease of installation on Windows 7. The main drawback for Microsoft’s SDK is that it only works for Windows 7, not even Windows XP. The SDK is free but limited to non-commercial purposes.
Results
Two major emotions, happiness and anger were taken into consideration. These two emotions were distinguished by only using the upper body data. Music was generated using motion of hands of the user as input. Emotional data was used to normalize the music generated to map it onto a musical scale so that it sounded aesthetically pleasing.
Discussion
Where body language is a crucial part of emotional detection, either by another human or a computer device, it is not complete. Current state of body language largely depends on the context. For example, people playing tennis would depict different emotions differently through body language than people playing piano. This is because in each of the situation, body language will have different constraints and the subject can only show movement in certain directions.
Secondly, real-time generation of music according to the emotion, and which also sounds that way to an untrained ear also lacks accuracy.
Conclusion
We conclude that body language alone is not sufficient for accurately determining the emotion of a person. But, coupled with facial expression analysis and vocal analysis, these three complete the method in which emotions are perceived by human beings and hence, it does have the potential of increasing the computer-aided emotion detection.
Hello Learners, in this tutorial, we will be learning about making an emotion predictor using a webcam on your system with machine learning in Python. For this, we need to have a d…. Read MoreSpeech Emotion Recognition in Python
Ever wondered, what if your camera could tell you the state of your mind based on its interpretation of your facial expression? Facial expression detection using Machine Learning i…. Read MoreUse of numpy.min_scalar_type( ) method in Python
By Adarsh Srivastava
In this tutorial, we will learn the use of the numpy.min_scalar_type( ) method in Python with some basic and easy examples. In many situations, you may come across such a function …. Read MoreHow to add Emojis in a Python Program
By Kunal Gupta
Hello everyone, In this tutorial, we’ll be learning how we can add Emojis in a Python Program. Emojis are a visual representation of an emotion or an entity from various genr…. Read More
And one more thing you have to keep in mind that here we are going to work with microphone thus you must need to know the device ID of your audio input device.
Because you have to tell your Python program that you want to take speech input or voice input from which particular microphone.
If you still don’t know how to find the device ID please read my previous tutorial,
The above tutorial will help you to learn all the things you need to set before you start working with this tutorial.
Now we assume that you are all set.
Take voice input from the user in Python using PyAudio – speech_recognizer
What we gonna do in simple steps:
Take input from the mic
Convert the voice or speech to text
Store the text in a variable/or you can directly take it as user input
There are several API available online for speech recognition or you can say voice to text.Sphinx can work offline.But I personally like google speech recognition as this gives us a more accurate result as Google has a huge dataset.Here I will work with Google Speech Recognition only. As it is not possible to cover all the speech recognition API in a single tutorial.Let’s start with the below code to check if everything is working fine or not.import speech_recognition as s_rprint(s_r.__version__)
Output:
3.8.1
It will print the current version of your speech recognition package.
If everything is fine then go to the next part.
Set microphone to accept sound
my_mic = s_r.Microphone()
Here you have to pass the parameter device_index=?
To recognize input from the microphone you have to use a recognizer class. Let’s just create one.
r = s_r.Recognizer()
So our program will be like this till now:import speech_recognition as s_rprint(s_r.__version__) # just to print the version not requiredr = s_r.Recognizer()my_mic = s_r.Microphone(device_index=1) #my device index is 1, you have to put your device index
Don’t try to run this program. We have left things to do.
Now we have to capture audio from microphone. To do that we can use the below code:with my_mic as source: print(“Say now!!!!”) audio = r.listen(source)
Now the final step to convert the sound taken from the microphone into text.
Convert the sound or speech into text in Python
To convert using Google speech recognition we can use the following line:
r.recognize_google(audio)
It will return a string with some texts. ( It will convert your voice to texts and return that as a string.
You can simply print it using the below line:
print(r.recognize_google(audio))
Now the full program will look like this:import speech_recognition as s_rprint(s_r.__version__) # just to print the version not requiredr = s_r.Recognizer()my_mic = s_r.Microphone(device_index=1) #my device index is 1, you have to put your device indexwith my_mic as source: print(“Say now!!!!”) audio = r.listen(source) #take voice input from the microphoneprint(r.recognize_google(audio)) #to print voice into text
If you run this you should get an output. But after waiting a few moments if you don’t get any output, check your internet connection. This program requires internet connection.
If your internet is alright but you still are not getting any output that means your microphone is getting noise.
Just press ctrl+c and hit enter to stop the current execution.
Now you have to reduce noise from your input.
How to do that?
r.adjust_for_ambient_noise(source)
This will be helpful for you.
Now the final program will be like this:
It should successfully work:import speech_recognition as s_rprint(s_r.__version__) # just to print the version not requiredr = s_r.Recognizer()my_mic = s_r.Microphone(device_index=1) #my device index is 1, you have to put your device indexwith my_mic as source: print(“Say now!!!!”) r.adjust_for_ambient_noise(source) #reduce noise audio = r.listen(source) #take voice input from the microphoneprint(r.recognize_google(audio)) #to print voice into text
Output:
Will print whatever you say!!
You can store the string to any variable if you want. But remember r.recognize_google(audio) this will return string. So careful while working with datatypes.
my_string = r.recognize_google(audio)
You can use this to store your speech in a variable.
by Evaggelos Spyrou 1,2,3,*,Rozalia Nikopoulou 4,Ioannis Vernikos 2 andPhivos Mylonas 41Institute of Informatics and Telecommunications, National Centre for Scientific Research “Demokritos”, 15341 Athens, Greece2Department of Computer Science, University of Thessaly, 38221 Lamia, Greece3Department of Computer Engineering T.E., Technological Education Institute of Sterea Ellada, 34400 Lamia, Greece4Department of Informatics, Ionian University, 49132 Corfu, Greece*Author to whom correspondence should be addressed.†This paper is an extended version of our paper published in Proceedings of the 11th PErvasive Technologies Related to Assistive Environments Conference, Corfu, Greece, 26–26 June 2018; pp. 106–107.Technologies2019, 7(1), 20; https://doi.org/10.3390/technologies7010020Received: 30 November 2018 / Revised: 21 January 2019 / Accepted: 30 January 2019 / Published: 4 February 2019(This article belongs to the Special Issue The PErvasive Technologies Related to Assistive Environments (PETRA))Download PDFBrowse FiguresCitation Export
Abstract
It is noteworthy nowadays that monitoring and understanding a human’s emotional state plays a key role in the current and forthcoming computational technologies. On the other hand, this monitoring and analysis should be as unobtrusive as possible, since in our era the digital world has been smoothly adopted in everyday life activities. In this framework and within the domain of assessing humans’ affective state during their educational training, the most popular way to go is to use sensory equipment that would allow their observing without involving any kind of direct contact. Thus, in this work, we focus on human emotion recognition from audio stimuli (i.e., human speech) using a novel approach based on a computer vision inspired methodology, namely the bag-of-visual words method, applied on several audio segment spectrograms. The latter are considered to be the visual representation of the considered audio segment and may be analyzed by exploiting well-known traditional computer vision techniques, such as construction of a visual vocabulary, extraction of speeded-up robust features (SURF) features, quantization into a set of visual words, and image histogram construction. As a last step, support vector machines (SVM) classifiers are trained based on the aforementioned information. Finally, to further generalize the herein proposed approach, we utilize publicly available datasets from several human languages to perform cross-language experiments, both in terms of actor-created and real-life ones.Keywords: emotion recognition; bag-of-visual words; spectrograms
1. Introduction
The recognition of a human’s emotional state constitutes one of the most recent trends in the field of human computer interaction [1]. During the last few years, many approaches have been proposed that make use of either sensors placed in the users’ environments (e.g., cameras and microphones), or even sensors placed on the users’ bodies (e.g., physiological or inertial sensors). Although during the last few years people are shifting from text to video, when they need to publicly express themselves [2], when observed by either cameras or microphones, they typically feel that their privacy is violated [3]. Of course, the use of body sensors for long time periods is a factor that may also cause discomfort. Among the least invasive approaches, those that make use of microphone sensors placed on the users’ environment and capturing their speech are usually considered. Vocalized speech is composed of two discrete parts. The first one is the linguistic content of speech; it consists of the articulated patterns that are pronounced by the speaker, i.e., what the speaker said. The second component of speech is its non-linguistic content, i.e., how the speaker pronounced it [4]. More specifically, the non-linguistic content of speech consists of the variation of the pronunciation of the articulated patterns, i.e., the acoustic aspect of speech. Typically, the description of linguistic patterns is qualitative. On the other hand, low-level features may be extracted from the non-linguistic ones, such as the rhythm, the pitch, the intensity, etc. Many emotion classification approaches from speech work based on both types of information.Moreover, linguistic patterns are typically extracted by using an automatic speech recognition system (ASR). However, the main drawback of such approaches is that they do not easily provide language-independent models. This happens since a plethora of different sentences, speakers, speaking styles and rates exist [5]. On the other hand, approaches based on non-linguistic features are often more robust to different languages. Of course, even when such features are used, the problem of emotion recognition from speech is still a challenging one. The main reason is that, even in this case, non-linguistic content may significantly vary due to factors such as cultural particularities. Sometimes, a potential chronic emotional state of a given speaker may play a serious role.Choosing the right approach in education is rather challenging. A classroom is an emotional setting on its own. Students’ emotions affect the way they learn as well as the way they put their abilities to use. There has not been enough research on how to manage or even neutralize the affect of emotions (not the emotion itself), so as to help students learn regardless of their emotional state. In order to manage emotions, it is critical to be able to identify them. Moreover, when it comes to distance or electronic learning, it is essential for educators to identify their students’ emotions so as be able to alter their teaching according to their students needs. In the case of a classroom (whether a real-world or a virtual one), any approach should be as less invasive as possible so as the students do not feel that “they are been watched,” in order to freely express their emotions. Adaptation of learning contexts could be helpful to improve both learning and negative emotions [6].The majority of approaches that use the non-linguistic component of speech typically rely on the extraction of spectral or cepstral features from the raw audio speech signals [4]. Contrary to previous works, we do not extract any audio features herein. Instead, we propose a computer vision approach that is applied on spectrogram representations of audio segments. More specifically, a spectrogram is a visual representation of the spectrum of the frequencies of a signal, as they vary with time. A spectrogram is a 2D signal that may be treated as if it were an image. Thus, we apply an algorithm derived from computer vision known as “Bag-of-Words” (BoW) or “Bag-of-Visual Words” (BoVW) model [7]. It should be noted here that, in a previous work [8], we have first experimented with this model and obtained promising results using several well-known datasets.In this work, we provide a thorough investigation of the BoVW model on its application to audio spectrograms, and by utilizing publicly available datasets of several languages. We perform cross-language experiments and also experiments where datasets have been contaminated with artificial noise. Moreover, apart from using datasets that have been created using actors, we also present a real-life experiment. More specifically, we have applied the proposed methodology in a real-life classroom environment, using a group of middle-school students and conducted an experiment where they were asked to freely express their unbiased opinion regarding the exercise they participated. The outcomes of the interviews (i.e., the resulting recordings) were annotated and used for emotion classification.The structure of the rest of this paper is as follows: in Section 2, we present related works on emotion recognition from audio, focusing on applications in education. Then, in Section 3, we describe in detail the Bag-of-Visual Words model and the proposed emotion classification strategy. The data sets that have been used and the series of experiments that have been performed are presented in Section 4. Finally, results are discussed and conclusions are drawn in Section 5, where some of our future plans for the application of emotion recognition in education are also presented.
2. Related Work
2.1. Non-Linguistic Approaches for Emotion Recognition
Emotion recognition from the non-linguistic component of multimedia documents containing speech has been typically based on the extraction of several low-level features which were then used to train models and map them to the underlying emotions. Such research efforts [9,10,11] in many cases included fusion of multimodal features such as audiovisual signals. Wang and Guan [9] introduced such a system that combined audio characteristics extracted using Mel-frequency Cepstral Coefficient (MFCC), along with a face detection scheme based on the hue, saturation, value (HSV) color model. Experimental results showed an effectiveness in emotion recognition that according to the authors rates up to 82.14%. In case of music signals, several efforts have turned to the recognition of their affective content with applications to affect-based retrieval from music databases [12,13] using audio content analysis so as to retrieve information related to emotion, using different hierarchical as well as non-hierarchical methods. Well-known classifiers have been used, e.g., Hidden Markov Models or Support Vector Machines, to extract features to emotional states. Such states either include fear, happiness, anger etc. [9,10], or in other cases [14,15,16] follow the dimensional approach [17] that originates from psychophysiology. Spectrograms have also been previously used for other audio analysis-related tasks, such as content classification [18] and segmentation [19], for stress recognition [20] and more recently for emotion recognition with convolutional neural networks [21,22].
2.2. Emotion Recognition in Education
Many definitions exist in the literature for the term emotion. One of the generally accepted ones defines an emotion as a “reaction to stimuli that can last for seconds or minutes” [23]. Moreover, schooling is an emotional process for all parties involved (student, teacher, parent), whereas emotions are involved in every aspect of the teaching and learning processes. In order to create a collaborative environment, teachers attempt to understand their students’ experiences, prior knowledge and emotions. Such understanding could provide educators with the necessary tools to create engaging and comprehensive lessons so as to fulfill their educational goals [24]. A student’s emotional state can affect their concentration, the quality of information they receive and process, their problem solving skills as well as their decision-making skills [25,26]. Therefore, instead of emphasizing on scores and tests, educators who seek educational reform aim at transforming their teaching so as to reflect their students needs and emotions.In principle, the teacher–student relationship has proven to affect a student’s performance in school; a positive teacher–student relationship leads to an engaged and higher competent performance [27]. Within the school environment, emotions can interfere with attention, facilitate or disrupt problem solving and are triggered by both teachers and students’ goals and expectations. Therefore, it is important for students’ educational progress to manage and regulate their emotions, whereas “downregulating” negative emotions and “upregulating” positive emotions tend to be the most common goal in education [28]. Emotion regulation [29]—a group of processes that a person could use in order to hold on, transform, control or change both positive or negative emotions [30]—enables students and teachers to avoid negative emotions and enhance positive emotions. Research shows that Emotion Regulation strategies in the classroom, e.g., reflection, reappraisal, rumination, distraction, expressive suppression, and social sharing [31], could lead to a positive educational outcome. Those strategies may vary since not all people express or process emotions in the same way and teachers should choose between or combine emotion regulation strategies keeping in mind the plethora as well as amalgam of different personalities within a classroom so as to manage the demands both of an entire classroom as well as of a student individually.In recent years, there has been plenty of research works analyzing the importance of emotion recognition and regulation in different scientific areas (e.g., psychology, AI, education, training, etc.) along with several types of software developed in an attempt to automatically recognize and analyze emotion via facial expressions, speech, attaching sensors, as well as hand and/or body gestures. It has become rather important lately to identify emotions during certain states (learning, working, etc.), so as to improve an individual’s performance. There is evidence through research which shows that certain emotions support learning processes, while other emotions suppress them [25]. Other research works indicated that students and teachers with positive emotions can produce better ideas and result to a better outcome. Positive emotions enhance levels of motivation, whereas negative emotions can reduce working memory [32]. Emotion also affects the way the brain works. According to [33], when a student is under stress, a major part of the brain “shuts down” and turns into “survival mode,” expressing emotions such as defensiveness [29], making clear that the way a student’s brain operates may affect the way they learn and adapt into the school environment.As for applications of emotion recognition in education, the focus is typically given on moral emotions (guilt, remorse, shame), which differ from the basic ones (sadness, happiness, etc.) [34]. In addition, virtual agents have been used in the role of educator [35] which were provided with the ability to sense the emotional state of the students. Upon emotion recognition, these agents could then make interaction more appealing for the students. Bahreini et al. [36] examined the advantages of speech emotion recognition in e-learning, in order to facilitate smoother interaction between humans and computers. A type of software developed to recognize emotion is the Framework for Improving Learning Through Webcams And Microphones (FILTWAM). FILTWAM software [37] was developed in order to provide real-time online feedback to e-learning educators using both facial and voice emotion recognition. According to the authors, FILTWAM allows continual observation of the learners’ behavior which then “translates” to emotions with an overall accuracy of 67% [36]. Another way to identify emotion is by using emotion sensors in intelligent tutors and facial detection software [38], by collecting data streams from students. In classroom experiments, this approach indicated a success of 60% in predicting students’ emotions. Kim et al. [39], on the other hand, proposed a smart classroom system which allows real-time suggestions so as the teacher/presenter can make adjustments to their non-verbal behavior in order to make their presentation more effective. Challenges lie in the creation of a holistic system and an algorithmic adaptation in order to allow real-time execution and quantification of valid educational variables for use in algorithms. The MaTHiSiS project [40,41] is introduced as an end-to-end solution aiming at each learner’s personal needs. This educational ecosystem uses sensing devices such as cameras, microphones, etc. and aims at engaging learners to the learning activities adjusting to their skill level as needed so as to decrease boredom and anxiety and increase the learning outcome taking into consideration any learning or physical disabilities.
3. Emotion Recognition from Spectrograms Using BoVW
In the following subsections, we focus on the Bag-of-Visual Words model, on which the herein presented approach is based. In addition, we describe the spectrogram generation process and we present the proposed computer vision-based emotion recognition methodology in attempt to illustrate the innovative aspects of our work.
3.1. The BoVW Model
The origin of the Bag-of-Words (BoW) model goes back to the 1950s and to the field of text document analysis [42]. In that case, the main idea was to describe a text document (either at its whole, or a small part) by using a histogram that is constructed on word frequencies. This idea, during the 2000s, has been adopted accordingly in order to suit the needs of several computer vision-related tasks. Notable examples include high-level visual concept detection, image classification, object/scene recognition problems [43], etc. The adopted model is often referred to as the “Bag-of-Visual Words” (BoVW) model.BoVW is a weakly supervised model, built upon the notion of visual vocabularies. A visual vocabulary V={wi},i=1,2,…,N is actually a set of “exemplar” image patches, which are commonly referred to as “visual words.” Using such a vocabulary, a given image may be described based on these words. To built an appropriate visual vocabulary, one should use a large corpus of representative images of the domain of interest, so that they would be closely related to the problem at hand. Typically, a clustering approach such as the well-known k-means algorithm is applied on the extracted features. The centroids (or in some cases the medoids) that result upon the application of clustering are then selected as the words (wi) that comprise the visual vocabulary. The size N of the visual vocabulary is typically determined heuristically, upon a trial-and-error or an extensive evaluation of various vocabulary sizes. Note that the visual vocabulary acts as a means of quantization of the feature space; it consists of the locally-extracted descriptors, which are accordingly quantized to their nearest word.More specifically, any given image is described by a feature vector (histogram) consisting of frequencies of visual words. The latter originates from the constructed visual vocabulary. In order to construct such description, features are first extracted using the exact method that was used during the vocabulary construction process, e.g., the same description, tuned with the same parameters. Each feature is then translated (i.e., quantized) to the most similar visual word of the vocabulary, using an appropriate similarity metric. The majority of approaches adopt the well-known Euclidean distance. This way, a histogram of visual words is extracted and is then used for the description of the whole image. It is represented using a 1×N-dimensional feature vector; the i-th component of the feature vector corresponds to the i-th visual word, i.e., wi, while its value denotes the appearance frequency of this word within the whole image. Note that one of the main advantages of BoVW is that it provides a fixed-size representation of the image, i.e., N is independent of the number of features that have been originally extracted. This property is important, since, in many widely used feature extraction approaches, such as salient point extraction, the number of feature varies depending on the image content which often makes their use non-trivial. In contrast to this case, the fixed size feature vectors generated by BoVW may be easily used to train several well-known classifiers and models, such as neural networks and support vector machines.
3.2. Spectrogram Generation
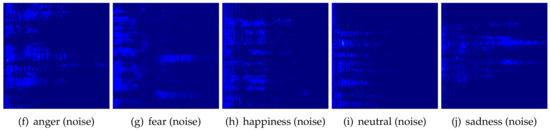
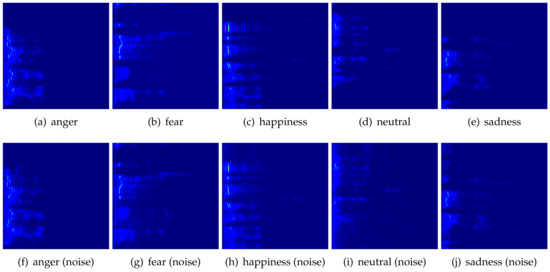
Moving on to the generation of spectrograms, we first extract a single segment of length ts sec from any given audio sample. This segment is randomly selected from the entire sample. Then, we apply the Short-Time Fourier Transform (STFT) on the original signal. We use short-term windows of fixed size tw and step ts. Pseudocolored images of spectrograms from five emotions that have been used within the experimental evaluation of this work are illustrated in Figure 1, Figure 2, Figure 3 and Figure 4. In order to evaluate our approach in the present of noise, before extracting the spectrogram of each training sample, we added a background sound (i.e., music, playing the role of noise) in three different Signal-To-Noise ratios (SNRs) (5, 4 and 3) for the crop of the original audio sample.
Figure 1. Example pseudocolored spectrogram images per emotion that have been generated from the EMOVO [44] dataset. First row: actual audio segments; second row: audio segments with added noise (the figure is best viewed in color, images have been post-processed for illustration purposes).
Figure 2. Example pseudocolored spectrogram images per emotion that have been generated from the EMO-DB [45] dataset. First row: actual audio segments; second row: audio segments with added noise (the figure is best viewed in color, images have been post-processed for illustration purposes).
Figure 3. Example pseudocolored spectrogram images per emotion that have been generated from the SAVEE [46] dataset. First row: actual audio segments; second row: audio segments with added noise (the figure is best viewed in color, images have been post-processed for illustration purposes).
Figure 4. Example pseudocolored spectrogram images per emotion that have been generated from the movies dataset. First row: actual audio segments; second row: audio segments with added noise (the figure is best viewed in color, images have been post-processed for illustration purposes).
3.3. Emotion Recognition Using BoVW
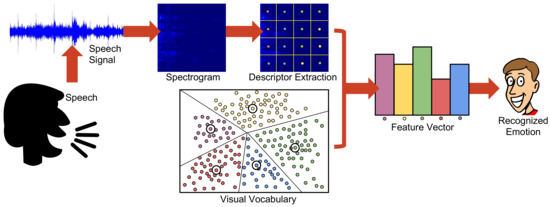
As a last step and regarding the extraction of visual features from spectrograms, we adopted a grid-based approach. Contrary to salient point approaches that first extract a set of points and extract descriptions from patches surrounding them, the first step of a grid-based approach is the selection of a rectangular grid. Each crossing of the grid is used to define a point (pixel) of interest. More specifically, we use a regular, i.e., square grid. From each resulting pixel, we extract the widely used Speeded-Up Robust Features (SURF) [47]. SURF are well-known for combining fast extraction speed, while being robust to several transformations and also illumination changes. Therefore, they have been adopted in many real-life computer-vision problems. Note that, in principle, SURF is both a salient point extraction and description scheme, yet we omit the first step and only use the latter. Although SURF salient regions have been effectively used into BoVW problems [48], in our case, initial experiments with part of the dataset indicated that the extracted number of points was rather small, and insufficient to produce effective histograms. Moreover, it has been demonstrated in [49] that the regions that result from grid-based image sampling may also carry useful information, which is in general adequate to provide a content description that can be used in classification schemes. For classification, we trained support vector machines (SVMs) with kernels on the extracted feature vectors. In Figure 5, we illustrate a visual overview of the whole process, which may be summarized by the following steps: (a) capturing of raw speech signal; (b) spectrogram generation; (c) descriptor extraction; (d) feature vector generation based on a previously constructed visual vocabulary; and (e) emotion recognition by feature vector classification using a previously trained SVM classifier.
Figure 5. A visual overview of the proposed emotion recognition scheme (the figure is best viewed in color).
4. Experiments
In this section, we describe the artificial datasets that we have used and also the real-life one that has been created within a classroom experiment. Moreover, we present several implementation details and also the results of the performed experiments.
4.1. Artificial Datasets
The first part of our experimental evaluation consisted of experiments using three widely known and freely available datasets of three different languages and also another custom dataset. More specifically, we used: (a) EMOVO [44], which is an emotional speech dataset in Italian. Six actors (three women/three men) performed 14 sentences, simulating six emotional states, i.e., disgust, fear, anger, joy, surprise, sadness plus the neutral state; (b) SAVEE [46], which is a larger emotional speech dataset in English. Four native English male speakers performed each 15 sentences per emotion, representing the same emotions as in EMOVO; (c) EMO-DB [45], which is an emotional speech dataset in German. Five male and 5 female actors performed 493 utterances in total, simulating anger, boredom, disgust, fear, happiness, sadness and neutral. The recordings were collected in an anechoic chamber with high-quality recording equipment; and (d) MOVIES which is a custom made dataset that has been annotated by several researchers of NCSR-“Demokritos.” It includes audio samples gathered from movies. All the movies used for the creation of this dataset were in English except one that was in Portuguese. Note that this sample was omitted from our evaluation, so that this dataset may be considered as a fully english one. For our task, we chose 5 of the common emotion classes, namely Happiness, Sadness, Anger, Fear and Neutral.
4.2. Real-Life Classroom Experiment
The in-classroom experiment, involved 24 middle school students (15 males/9 females). It was conducted within a school computer laboratory in Corfu, Greece. The participants were all aged between 12–13 years old. They all had some prior knowledge on robotic building and coding, since they had taken such courses in the past. During the experiment, their Information and Communications Technology (ICT) teacher was present the entire time. Her duties were (a) to describe in detail the task given, so that students would be able to accomplish it without any external help; and (b) to document their reactions during the experiments. Students were familiar with their teacher, so their emotional reactions were expected to be authentic and they were randomly divided into two teams. Specific care was taken so that both teams consisted of both male and female students and contained members of various levels of robotics’ knowledge. Each team was assigned with a different task which involved building and programming an educational robot using LEGO Mindstorm EVE 3 Educational kit [50]. Note that both tasks were considered to be of the same difficulty level. Programming involved both the Lego Mindstorm software and MIT Scratch [51]. It is rather important to point out that all students involved have volunteered to take this course among several other options and were in general satisfied with the use of Mindstorm kits in many previous activities.The first team was instructed to program the robot to perform several tasks such as “move forward”, “turn right”, “turn left”, and “lift and drop certain small objects”. Controlling the robot was performed via a smart mobile phone. The second team was instructed to program the robot to follow a pre-defined route (using simple “line-follow”) by equipping the robot with an Red-Green-Blue (RGB) color sensor, select small LEGO bricks of red color only and push them outside of the canvas. Both teams were not given any instructions about the size or type of robot, and there were no further instructions or interference by the instructor. Upon the completion of the tasks, students were interviewed separately by the instructor and they were asked to describe their experience encouraging them to express their emotions during the whole procedure. The interviews were recorded using a computer microphone and annotated based on the students’ vocal and facial appearance, according to the instructor’s experience. Special care had been taken so that all recordings took place within an environment free of ambient noises. Additionally, recordings were post-processed using the Audacity Software [52], in order to remove parts with silence and/or the voice of the instructor. This way, we ended up with 42 recordings, with an average duration of 7.8 seconds. Upon the annotation process, the dataset consisted of 24 samples with a positive emotion, eight with a negative and ten with a neutral. We shall refer to this dataset in the following as “kids”.
4.3. Results
In both cases, we experimented with segments with tS=1 and TS=2 sec, tw=40 msec and step ts=20 msec. For the vocabulary size, we used N=100,200,…,1500. The BoVW model has been implemented using the Computer Vision Toolbox of Matlab R2017a (R2017a, MathWorks, Natick, MA, USA) [53]. We used a grid of size 8×8. The spectrograms have sizes 227×227 px and have been extracted using the pyAudioAnalysis open source Python library [54].To validate the effectiveness of our approach, we have designed a series of experiments. Note that we also perform multilingual experiments, i.e., training and evaluation sets are comprised by audio samples originating from different languages. We remind that, in all cases, the emotion classes are Happiness, Sadness, Anger, Fear and Neutral. To imitate real-life situations where recognition takes place within a noisy environment, we have also added noisy samples, as we have already described in Section 3.2.Validity threats during the experiment both internal and/or external have been identified so as to be avoided or controlled. Internal threats consisted of (a) the lack of understanding the process of the experiment by the students; (b) the possibility of the participants’ fatigue during the experiment; (c) the level of students’ academic performance and ability; and (d) the possibility of one or more students dropping out due to lack of interest. The only external threat consisted of the number of students participating; this could mean that the results are under-represented.At each experiment, we keep the 90% of the samples of the smallest class for training. All remaining samples are used for evaluation. We run each experiment 10 times and we estimate the average F1 score. Then, in Table 1, we report the best average F1 score, in terms of the visual vocabulary size N. In the first series of experiments, samples originating from the same language are included in both training and validation sets for the cases of both regular and noisy samples. In this case, best results were achieved in all experiments by using visual vocabularies of size N so that 1100 ≤N≤ 1500. In the second series of experiments, we aimed to assess whether the proposed approach may be used for cross-language scenarios. A major difficulty in such cases is the great differences between languages, since, besides the linguistic differences, there are also cultural ones, i.e., big variability in the way each emotion is expressed. To this goal, training and testing do not contain samples from the same language. In that case, best results were achieved in all experiments by using visual vocabularies of size N so that 100 ≤N≤ 400. As it may be observed in Table 1, in many cases, the proposed approach shows adequate performance in cross-language experiments. In particular, the more training sets that are available, the bigger the increase of performance is observed. Moreover, in all cases, it is robust to noise showing in all cases of comparable performance.Table 1. Experimental results for emotion recognition using all possible combinations of training and testing data sets, with the best vocabulary size per case.
We compared our approach with a baseline one (which will be referred to as “baseline 1”) that used an SVM classifier using an early fusion approach on standard features. More specifically, we used Histograms of Oriented Gradients (HOGs) [55], Local Binary Patterns [56] and histograms of color coefficients. Feature extraction has been performed in a 2×2 grid rationale, i.e., all features have been computed on four grids and then the resulting feature vectors were merged to a single feature vector that represents the whole image. We also compared our approach to one that was based on early fusion of several short-term audio features (which will be referred to as “baseline 2”), i.e., features extracted on the speech signal. These features have been extracted using [54] and are zero-crossing rate, energy, entropy of energy, spectral centroid, spectral spread, spectral entropy, spectral flux, spectral rolloff, mel frequency cepstral coefficients, a chroma vector and the chroma deviation. As it may be observed in Table 2, in almost all cases, the proposed BoVW scheme outperformed the baseline approaches. Note that, for comparisons, we did not perform any cross-language experiment. In addition, in case of the kids dataset, since it originated from a significantly different domain, we felt that we should not use it in cross-language experiments.Table 2. Comparative results of the proposed method with two baselines, in terms of F1 score and for all five aforementioned datasets (EMOVO, SAVEE, EMO-DB, movies, kids)—numbers in bold indicate best performance value.
5. Conclusions and Future Work
In education, there is a difficulty in recognizing as well as regulating the emotions of children and this is where current state-of-the-art research and technology “steps-in” to assist the educator to identify emotions in a faster and a more sufficient way so as to try and control any negative outcome.In this framework, we presented herein an approach for recognizing the emotional state of humans, relying only on audio information. More specifically, our approach extracts non-linguistic information from spectrograms that represent audio segments. From each spectrogram, we overlaid a sampling grid and extracted a set of interest points. From each, we extracted SURF features and used them to train a BoVW model, which was then used for emotion classification with SVMs. We evaluated the proposed approach on three publicly available artificial datasets. On top of that, we created a dataset that consisted of real-life recordings from middle-school students. Our experimental results show that, in almost all cases, the proposed approach outperformed two baseline approaches: one that also worked on visual features from spectrograms and another that relied on audio spectral features. It should be also pointed out that our approach does not rely at any step on spectral features. Within our future work, we plan to enhance the application domain of our methodology and perform experiments targeting on students with learning difficulties, where emotion expression is somehow more difficult to retrieve and assess. Furthermore, we plan to conduct research on how this system could evolve, so as to be used as a stealth assessment technique, in order to extract real-time information from students, evaluate students’ acquired knowledge, make accurate inferences of competencies and manage to react in immediate and meaningful ways.In conclusion, we feel that emotion recognition is a research area that will attract interest of many application areas, apart from education. We feel that most popular fields of application may include: (a) dynamical marketing which would become adaptive to the emotional reactions of users (i.e., of potential customers); (b) smart cars, i.e., for recognizing the drivers’ emotional states e.g., for the prevention of accidents due to an unpleasant one; (c) evaluation of personality of candidates e.g., during an interview; (d) evaluation either of employees or of satisfaction acquired by users during their interaction e.g., in call centers; and (e) enhancing gaming experience by understanding the players’ emotional response and dynamically changing the scenario of the game.
Author Contributions
The conceptualization of the approach was done by E.S., R.N., I.V., and P.M.; E.S., and P.M. performed the theoretical analysis, R.N., and I.V. focused on the practical analysis and experimentation. E.S., R.N., I.V., and P.M. validated the theoretical analysis and experimentation results. P.M., and E.S. supervised the process. All authors analyzed the results, and contributed to writing and reviewing the manuscript.
Funding
This research has been co-financed by the European Union and Greek national funds through the Operational Program Competitiveness, Entrepreneurship and Innovation, under the call RESEARCH–CREATE–INNOVATE (project code: T1EDK-02070). Part of work presented in this document is a result of the MaTHiSiS project. This project has received funding from the European Union’s Horizon 2020 Programme (H2020-ICT-2015) under Grant No. 687772.
Poria, S.; Chaturvedi, I.; Cambria, E.; Hussain, A. Convolutional MKL based multimodal emotion recognition and sentiment analysis. In Proceedings of the 2016 IEEE 16th International Conference on Data Mining, Barcelona, Spain, 12–15 December 2016; pp. 439–448. [Google Scholar]
Zeng, E.; Mare, S.; Roesner, F. End user security and privacy concerns with smart homes. In Proceedings of the Third Symposium on Usable Privacy and Security (SOUPS), Pittsburgh, PA, USA, 18–20 July 2007. [Google Scholar]
Anagnostopoulos, C.N.; Iliou, T.; Giannoukos, I. Features and classifiers for emotion recognition from speech: A survey from 2000 to 2011. Artif. Intell. Rev.2015, 43, 155–177. [Google Scholar] [CrossRef]
El Ayadi, M.; Kamel, M.S.; Karray, F. Survey on speech emotion recognition: Features, classification schemes, and databases. Pattern Recognit.2011, 44, 572–587. [Google Scholar] [CrossRef]
Alibali, M.W.; Knuth, E.J.; Hattikudur, S.; McNeil, N.M.; Stephens, A.C. A Longitudinal Examination of Middle School Students’ Understanding of the Equal Sign and Equivalent Equations. Math. Think. Learn.2007, 9, 221–247. [Google Scholar] [CrossRef]
Fei-Fei, L.; Perona, P. A bayesian hierarchical model for learning natural scene categories. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; Volume 2, pp. 524–531. [Google Scholar]
Spyrou, E.; Giannakopoulos, T.; Sgouropoulos, D.; Papakostas, M. Extracting emotions from speech using a bag-of-visual-words approach. In Proceedings of the 12th International Workshop on Semantic and Social Media Adaptation and Personalizationon, Bratislava, Slovakia, 9–10 July 2017; pp. 80–83. [Google Scholar]
Wang, Y.; Guan, L. Recognizing human emotional state from audiovisual signals. IEEE Trans. Multimedia2008, 10, 936–946. [Google Scholar] [CrossRef]
Hanjalic, A. Extracting moods from pictures and sounds: Towards truly personalized TV. IEEE Signal Process. Mag.2006, 23, 90–100. [Google Scholar] [CrossRef]
Lu, L.; Liu, D.; Zhang, H.J. Automatic mood detection and tracking of music audio signals. IEEE Trans. Audio Speech Lang. Process.2006, 14, 5–18. [Google Scholar] [CrossRef]
Yang, Y.H.; Lin, Y.C.; Su, Y.F.; Chen, H.H. A regression approach to music emotion recognition. IEEE Trans. Audio Speech Lang. Process.2008, 16, 448–457. [Google Scholar] [CrossRef]
Wöllmer, M.; Eyben, F.; Reiter, S.; Schuller, B.; Cox, C.; Douglas-Cowie, E.; Cowie, R. Abandoning emotion classes-towards continuous emotion recognition with modelling of long-range dependencies. In Proceedings of the INTERSPEECH 9th Annual Conference of the International Speech Communication Association, Brisbane, Australia, 22–26 September 2008; pp. 597–600. [Google Scholar]
Giannakopoulos, T.; Pikrakis, A.; Theodoridis, S. A dimensional approach to emotion recognition of speech from movies. In Proceedings of the 2009 IEEE International Conference on Acoustics, Speech and Signal Processing, Taipei, Taiwan, 19–24 April 2009; pp. 65–68. [Google Scholar]
Grimm, M.; Kroschel, K.; Mower, E.; Narayanan, S. Primitives-based evaluation and estimation of emotions in speech. Speech Commun.2007, 49, 787–800. [Google Scholar] [CrossRef]
Robert, P. Emotion: Theory, Research, and Experience. Vol. 1: Theories of Emotion; Academic Press: Cambridge, MA, USA, 1980. [Google Scholar]
Lee, H.; Pham, P.; Largman, Y.; Ng, A.Y. Unsupervised feature learning for audio classification using convolutional deep belief networks. In Proceedings of the 22nd International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 7–10 December 2009; pp. 1096–1104. [Google Scholar]
Zhang, T.; Kuo, C.C.J. Audio content analysis for online audiovisual data segmentation and classification. IEEE Trans. Speech Audio Process.2001, 9, 441–457. [Google Scholar] [CrossRef]
He, L.; Lech, M.; Maddage, N.; Allen, N. Stress and emotion recognition using log-Gabor filter analysis of speech spectrograms. In Proceedings of the 3rd International Conference on Affective Computing and Intelligent Interaction and Workshops, Amsterdam, Netherlands, 10–12 September 2009; pp. 1–6. [Google Scholar]
Mao, Q.; Dong, M.; Huang, Z.; Zhan, Y. Learning salient features for speech emotion recognition using convolutional neural networks. IEEE Trans. Multimedia2014, 16, 2203–2213. [Google Scholar] [CrossRef]
Papakostas, M.; Spyrou, E.; Giannakopoulos, T.; Siantikos, G.; Sgouropoulos, D.; Mylonas, P.; Makedon, F. Deep Visual Attributes vs. Hand-Crafted Audio Features on Multidomain Speech Emotion Recognition. Computation2017, 5, 26. [Google Scholar] [CrossRef]
Mahn, H.; John-Steiner, V. The gift of confidence: A Vygotskian view of emotions. In Learning for Life in the 21st Century: Sociocultural Perspectives on the Future of Education; Wiley: Hoboken, NJ, USA, 2002; pp. 46–58. [Google Scholar] [CrossRef]
Kołakowska, A.; Landowska, A.; Szwoch, M.; Szwoch, W.; Wrobel, M.R. Emotion recognition and its applications. Hum. Comput. Syst. Interact. Backgr. Appl.2014, 3, 51–62. [Google Scholar]
Sutton, R.E.; Wheatley, K.F. Teachers’ emotions and teaching: A review of the literature and directions for future research. Educ. Psychol. Rev.2003, 15, 327–358. [Google Scholar] [CrossRef]
Howes, C. Social-emotional classroom climate in child care, child-teacher relationships and children’s second grade peer relations. Soc. Dev.2000, 9, 191–204. [Google Scholar] [CrossRef]
Sutton, R.E. Emotional regulation goals and strategies of teachers. Soc. Psychol. Educ.2004, 7, 379–398. [Google Scholar] [CrossRef]
Fried, L. Teaching teachers about emotion regulation in the classroom. Aust. J. Teach. Educ.2011, 36, 3. [Google Scholar] [CrossRef]
Macklem, G.L. Practitioner’s Guide to Emotion Regulation in School-Aged Children; Springer Science and Business Media: New York, NY, USA, 2007. [Google Scholar]
Macklem, G.L. Boredom in the Classroom: Addressing Student Motivation, Self-Regulation, and Engagement in Learning; Springer: New York, NY, USA, 2015; Volume 1. [Google Scholar]
Linnenbrink, E.A.; Pintrich, P.R. Multiple pathways to learning and achievement: The role of goal orientation in fostering adaptive motivation, affect, and cognition. In Intrinsic and Extrinsic Motivation: The Search for Optimal Motivation and Performance; Sansone, C., Harackiewicz, J.M., Eds.; Academic Press: San Diego, CA, USA, 2000; pp. 195–227. [Google Scholar] [CrossRef]
Weare, K. Developing the Emotionally Literate School; Sage: London, UK, 2003. [Google Scholar]
Martiínez, J.G. Recognition and emotions. A critical approach on education. Procedia Soc. Behav. Sci.2012, 46, 3925–3930. [Google Scholar] [CrossRef]
Tickle, A.; Raghu, S.; Elshaw, M. Emotional recognition from the speech signal for a virtual education agent. J. Phys. Conf. Ser.2013, 450, 012053. [Google Scholar] [CrossRef]
Bahreini, K.; Nadolski, R.; Westera, W. Towards real-time speech emotion recognition for affective e-learning. Educ. Inf. Technol.2016, 21, 1367–1386. [Google Scholar] [CrossRef]
Bahreini, K.; Nadolski, R.; Qi, W.; Westera, W. FILTWAM—A framework for online game-based communication skills training—Using webcams and microphones for enhancing learner support. In The 6th European Conference on Games Based Learning (ECGBL); Felicia, P., Ed.; Academic Conferences and Publishing International: Reading, UK, 2012; pp. 39–48. [Google Scholar]
Arroyo, I.; Cooper, D.G.; Burleson, W.; Woolf, B.P.; Muldner, K.; Christopherson, R. Emotion sensors go to school. AIED2009, 200, 17–24. [Google Scholar]
Kim, Y.; Soyata, T.; Behnagh, R.F. Towards emotionally aware AI smart classroom: Current issues and directions for engineering and education. IEEE Access2018, 6, 5308–5331. [Google Scholar] [CrossRef]
Spyrou, E.; Vretos, N.; Pomazanskyi, A.; Asteriadis, S.; Leligou, H.C. Exploiting IoT Technologies for Personalized Learning. In Proceedings of the 2018 IEEE Conference on Computational Intelligence and Games (CIG), Maastricht, The Netherlands, 14–17 August 2018; pp. 1–8. [Google Scholar]
Sivic, J.; Zisserman, A. Efficient visual search of videos cast as text retrieval. IEEE Trans. Pattern Anal. Mach. Intell.2009, 31, 591–606. [Google Scholar] [CrossRef] [PubMed]
Costantini, G.; Iaderola, I.; Paoloni, A.; Todisco, M. Emovo corpus: An italian emotional speech database. In Proceedings of the International Conference on Language Resources and Evaluation (LREC 2014), Reykjavik, Iceland, 26–31 May 2014; pp. 3501–3504. [Google Scholar]
Burkhardt, F.; Paeschke, A.; Rolfes, M.; Sendlmeier, W.F.; Weiss, B. A database of German emotional speech. In Proceedings of the Ninth European Conference on Speech Communication and Technology, Lisbon, Portugal, 4–8 September 2005. [Google Scholar]
Haq, S.; Jackson, P.J.; Edge, J. Speaker-dependent audio-visual emotion recognition. In Proceedings of the 2009 International Conference on Auditory-Visual Speech Processing, Norwich, UK, 10–13 September 2009; pp. 53–58. [Google Scholar]
Bay, H.; Ess, A.; Tuytelaars, T.; Van Gool, L. Speeded-up robust features (SURF). Comput. Vis. Image Underst.2008, 110, 346–359. [Google Scholar] [CrossRef]
Alfanindya, A.; Hashim, N.; Eswaran, C. Content Based Image Retrieval and Classification using speeded-up robust features (SURF) and grouped bag-of-visual-words (GBoVW). In Proceedings of the 2013 International Conference on Technology, Informatics, Management, Engineering and Environment, Bandung, Indonesia, 23–26 June 2013. [Google Scholar]
Tuytelaars, T. Dense interest points. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2281–2288. [Google Scholar]
MATLAB and Computer Vision Toolbox Release, 2017a; The MathWorks, Inc.: Natick, MA, USA.
Giannakopoulos, T. pyaudioanalysis: An open-source python library for audio signal analysis. PLoS ONE2015, 10, e0144610. [Google Scholar] [CrossRef] [PubMed]
Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
Guo, Z.; Zhang, L.; Zhang, D. A completed modeling of local binary pattern operator for texture classification. IEEE Trans. Image Process.2010, 19, 1657–1663. [Google Scholar] [PubMed]
Pathmind’s artificial intelligence wiki is a beginner’s guide to important topics in AI, machine learning, and deep learning. The goal is to give readers an intuition for how powerful new algorithms work and how they are used, along with code examples where possible.
Advances in the field of machine learning (algorithms that adjust themselves when exposed to data) are driving progress more widely in AI. But many terms and concepts will seem incomprehensible to the intelligent outsider, the beginner, and even the former student of AI returning to a transformed discipline after years away. We hope this wiki helps you better understand AI, the software used to build it, and what is at stake in its development.
The line between mathematics and philosophy is blurry when we talk about artificial intelligence, because with AI, we ask the mineral called silicon to perceive and to think – actions once thought exclusive to meat, and now possible with computation. We hope that by reading this wiki, you will find new ways of thinking about life and intelligence, just as we have by writing it.
Emotion recognition is the process of identifying human emotion. People vary widely in their accuracy at recognizing the emotions of others. Use of technology to help people with emotion recognition is a relatively nascent research area. Generally, the technology works best if it uses multiple modalities in context. To date, the most work has been conducted on automating the recognition of facial expressions from video, spoken expressions from audio, written expressions from text, and physiology as measured by wearables.
Contents
1Human
2Automatic
2.1Approaches
2.1.1Knowledge-based techniques
2.1.2Statistical methods
2.1.3Hybrid approaches
2.2Datasets
2.3Applications
3Subfields of emotion recognition
3.1Emotion recognition in text
3.2Emotion recognition in audio
3.3Emotion recognition in video
3.4Emotion recognition in conversation
4See also
5References
Human
Main article: Emotion perception
Humans show a great deal of variability in their abilities to recognize emotion. A key point to keep in mind when learning about automated emotion recognition is that there are several sources of “ground truth,” or truth about what the real emotion is. Suppose we are trying to recognize the emotions of Alex. One source is “what would most people say that Alex is feeling?” In this case, the ‘truth’ may not correspond to what Alex feels, but may correspond to what most people would say it looks like Alex feels. For example, Alex may actually feel sad, but he puts on a big smile and then most people say he looks happy. If an automated method achieves the same results as a group of observers it may be considered accurate, even if it does not actually measure what Alex truly feels. Another source of ‘truth’ is to ask Alex what he truly feels. This works if Alex has a good sense of his internal state, and wants to tell you what it is, and is capable of putting it accurately into words or a number. However, some people are alexithymic and do not have a good sense of their internal feelings, or they are not able to communicate them accurately with words and numbers. In general, getting to the truth of what emotion is actually present can take some work, can vary depending on the criteria that are selected, and will usually involve maintaining some level of uncertainty.
Automatic
Decades of scientific research have been conducted developing and evaluating methods for automated emotion recognition. There is now an extensive literature proposing and evaluating hundreds of different kinds of methods, leveraging techniques from multiple areas, such as signal processing, machine learning, computer vision, and speech processing. Different methodologies and techniques may be employed to interpret emotion such as Bayesian networks., aussian Mixture models and Hidden Markov Models.
Approaches
The accuracy of emotion recognition is usually improved when it combines the analysis of human expressions from multimodal forms such as texts, physiology, audio, or video. Different emotion types are detected through the integration of information from facial expressions, body movement and gestures, and speech. The technology is said to contribute in the emergence of the so-called emotional or emotive Internet.]
The existing approaches in emotion recognition to classify certain emotion types can be generally classified into three main categories: knowledge-based techniques, statistical methods, and hybrid approaches.
Knowledge-based techniques
Knowledge-based techniques (sometimes referred to as lexicon-based techniques), utilize domain knowledge and the semantic and syntactic characteristics of language in order to detect certain emotion types. In this approach, it is common to use knowledge-based resources during the emotion classification process such as WordNet, SenticNet, ConceptNet, and EmotiNet, to name a few. One of the advantages of this approach is the accessibility and economy brought about by the large availability of such knowledge-based resources. A limitation of this technique on the other hand, is its inability to handle concept nuances and complex linguistic rules
Knowledge-based techniques can be mainly classified into two categories: dictionary-based and corpus-based approaches. Dictionary-based approaches find opinion or emotion seed words in a dictionary and search for their synonyms and antonyms to expand the initial list of opinions or emotions. Corpus-based approaches on the other hand, start with a seed list of opinion or emotion words, and expand the database by finding other words with context-specific characteristics in a large corpus. While corpus-based approaches take into account context, their performance still vary in different domains since a word in one domain can have a different orientation in another domain.
Statistical methods
Statistical methods commonly involve the use of different supervised machinelearning algorithms in which a large set of annotated data is fed into the algorithms for the system to learn and predict the appropriate emotion types. Machine learning algorithms generally provide more reasonable classification accuracy compared to other approaches, but one of the challenges in achieving good results in the classification process, is the need to have a sufficiently large training set.
Some of the most commonly used machine learning algorithms include Support Vector Machines (SVM), Naive Bayes, and Maximum Entropy. Deep learning, which is under the unsupervised family of machine learning, is also widely employed in emotion recognition. Well-known deep learning algorithms include different architectures of Artificial Neural Network (ANN) such as Convolutional Neural Network (CNN), Long Short-term Memory (LSTM), and Extreme Learning Machine (ELM). The popularity of deep learning approaches in the domain of emotion recognition may be mainly attributed to its success in related applications such as in computer vision, speech recognition, and Natural Language Processing (NLP)
Hybrid approaches
Hybrid approaches in emotion recognition are essentially a combination of knowledge-based techniques and statistical methods, which exploit complementary characteristics from both techniques. Some of the works that have applied an ensemble of knowledge-driven linguistic elements and statistical methods include sentic computing and iFeel, both of which have adopted the concept-level knowledge-based resource SenticNet. The role of such knowledge-based resources in the implementation of hybrid approaches is highly important in the emotion classification process. Since hybrid techniques gain from the benefits offered by both knowledge-based and statistical approaches, they tend to have better classification performance as opposed to employing knowledge-based or statistical methods independently. A downside of using hybrid techniques however, is the computational complexity during the classification process.
Datasets
Data is an integral part of the existing approaches in emotion recognition and in most cases it is a challenge to obtain annotated data that is necessary to train machine learning algorithms. For the task of classifying different emotion types from multimodal sources in the form of texts, audio, videos or physiological signals, the following datasets are available:
HUMAINE: provides natural clips with emotion words and context labels in multiple modalities
Belfast database: provides clips with a wide range of emotions from TV programs and interview recordings
SEMAINE: provides audiovisual recordings between a person and a virtual agent and contains emotion annotations such as angry, happy, fear, disgust, sadness, contempt, and amusement
IEMOCAP: provides recordings of dyadic sessions between actors and contains emotion annotations such as happiness, anger, sadness, frustration, and neutral state
eNTERFACE: provides audiovisual recordings of subjects from seven nationalities and contains emotion annotations such as happiness, anger, sadness, surprise, disgust, and fear
DEAP: provides electroencephalography (EEG), electrocardiography (ECG), and face video recordings, as well as emotion annotations in terms of valence, arousal, and dominance of people watching film clips
DREAMER: provides electroencephalography (EEG) and electrocardiography (ECG) recordings, as well as emotion annotations in terms of valence, arousal, and dominance of people watching film clips
MELD: is a multiparty conversational dataset where each utterance is labeled with emotion and sentiment. MELD provides conversations in video format and hence suitable for multimodal emotion recognition and sentiment analysis. MELD is useful for multimodal sentiment analysis and emotion recognition, dialogue systems and emotion recognition in conversations.
MuSe: provides audiovisual recordings of natural interactions between a person and an object. It has discrete and continuous emotion annotations in terms of valence, arousal and trustworthiness as well as speech topics useful for multimodal sentiment analysis and emotion recognition.
UIT-VSMEC: is a standard Vietnamese Social Media Emotion Corpus (UIT-VSMEC) with about 6,927 human-annotated sentences with six emotion labels, contributing to emotion recognition research in Vietnamese which is a low-resource language in Natural Language Processing (NLP).
Applications
Emotion recognition is used in society for a variety of reasons. Affectiva, which spun out of MIT, provides artificial intelligence software that makes it more efficient to do tasks previously done manually by people, mainly to gather facial expression and vocal expression information related to specific contexts where viewers have consented to share this information. For example, instead of filling out a lengthy survey about how you feel at each point watching an educational video or advertisement, you can consent to have a camera watch your face and listen to what you say, and note during which parts of the experience you show expressions such as boredom, interest, confusion, or smiling. (Note that this does not imply it is reading your innermost feelings—it only reads what you express outwardly.) Other uses by Affectiva include helping children with autism, helping people who are blind to read facial expressions, helping robots interact more intelligently with people, and monitoring signs of attention while driving in an effort to enhance driver safety.
A patent filed by Snapchat in 2015 describes a method of extracting data about crowds at public events by performing algorithmic emotion recognition on users’ geotagged selfies.
Emotient was a startup company which applied emotion recognition to reading frowns, smiles, and other expressions on faces, namely artificial intelligence to predict “attitudes and actions based on facial expressions”. Apple bought Emotient in 2016 and uses emotion recognition technology to enhance the emotional intelligence of its products.
nViso provides real-time emotion recognition for web and mobile applications through a real-time API. Visage Technologies AB offers emotion estimation as a part of their Visage SDK for marketing and scientific research and similar purposes.]
Eyeris is an emotion recognition company that works with embedded system manufacturers including car makers and social robotic companies on integrating its face analytics and emotion recognition software; as well as with video content creators to help them measure the perceived effectiveness of their short and long form video creative.
Many products also exist to aggregate information from emotions communicated online, including via “like” button presses and via counts of positive and negative phrases in text and affect recognition is increasingly used in some kinds of games and virtual reality, both for educational purposes and to give players more natural control over their social avatars.
Subfields of emotion recognition
Emotion recognition is probably to gain the best outcome if applying multiple modalities by combining different objects, including text (conversation), audio, video, and physiology to detect emotions.
Emotion recognition in text
Text data is a favorable research object for emotion recognition when it is free and available everywhere in human life. Compare to other types of data, the storage of text data is lighter and easy to compress to the best performance due to the frequent repetition of words and characters in languages. Emotions can be extracted from two essential text forms: written texts and conversations (dialogues). For written texts, many scholars focus on working with sentence level to extract “words/phrases” representing emotions.]
Emotion recognition in audio
Different from emotion recognition in text, vocal signals are used for the recognition to extract emotions from audio.
Emotion recognition in video
Video data is a combination of audio data, image data and sometimes texts (in case of subtitles ).
Emotion recognition in conversation
Emotion recognition in conversation (ERC) extracts opinions between participants from massive conversational data in social platforms, such as Facebook, Twitter, YouTube, and others. ERC can take input data like text, audio, video or a combination form to detect several emotions such as fear, lust, pain, and pleasure.
^ Hari Krishna Vydana, P. Phani Kumar, K. Sri Rama Krishna and Anil Kumar Vuppala. “Improved emotion recognition using GMM-UBMs”. 2015 International Conference on Signal Processing and Communication Engineering Systems
^ Poria, Soujanya; Cambria, Erik; Bajpai, Rajiv; Hussain, Amir (September 2017). “A review of affective computing: From unimodal analysis to multimodal fusion”. Information Fusion. 37: 98–125. doi:10.1016/j.inffus.2017.02.003. hdl:1893/25490.
^ Caridakis, George; Castellano, Ginevra; Kessous, Loic; Raouzaiou, Amaryllis; Malatesta, Lori; Asteriadis, Stelios; Karpouzis, Kostas (19 September 2007). Multimodal emotion recognition from expressive faces, body gestures and speech. IFIP the International Federation for Information Processing. 247. pp. 375–388. doi:10.1007/978-0-387-74161-1_41. ISBN978-0-387-74160-4.
^ Hemmatian, Fatemeh; Sohrabi, Mohammad Karim (18 December 2017). “A survey on classification techniques for opinion mining and sentiment analysis”. Artificial Intelligence Review. 52 (3): 1495–1545. doi:10.1007/s10462-017-9599-6. S2CID11741285.
^ Jump up to:abc Sun, Shiliang; Luo, Chen; Chen, Junyu (July 2017). “A review of natural language processing techniques for opinion mining systems”. Information Fusion. 36: 10–25.doi:10.1016/j.inffus.2016.10.004.
^ Majumder, Navonil; Poria, Soujanya; Gelbukh, Alexander; Cambria, Erik (March 2017). “Deep Learning-Based Document Modeling for Personality Detection from Text”. IEEE Intelligent Systems. 32 (2): 74–79. doi:10.1109/MIS.2017.23. S2CID206468984.
^ Mahendhiran, P. D.; Kannimuthu, S. (May 2018). “Deep Learning Techniques for Polarity Classification in Multimodal Sentiment Analysis”. International Journal of Information Technology & Decision Making. 17 (3): 883–910.doi:10.1142/S0219622018500128.
^ Yu, Hongliang; Gui, Liangke; Madaio, Michael; Ogan, Amy; Cassell, Justine; Morency, Louis-Philippe (23 October 2017). Temporally Selective Attention Model for Social and Affective State Recognition in Multimedia Content. MM ’17. ACM. pp. 1743–1751. doi:10.1145/3123266.3123413. ISBN9781450349062. S2CID3148578.
^ Poria, Soujanya; Hazarika, Devamanyu; Majumder, Navonil; Naik, Gautam; Cambria, Erik; Mihalcea, Rada (2019). “MELD: A Multimodal Multi-Party Dataset for Emotion Recognition in Conversations”. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA, USA: Association for Computational Linguistics: 527–536. arXiv:1810.02508. doi:10.18653/v1/p19-1050. S2CID52932143.
^ Stappen, Lukas; Schuller, Björn; Lefter, Iulia; Cambria, Erik; Kompatsiaris, Ioannis (2020). “Summary of MuSe 2020: Multimodal Sentiment Analysis, Emotion-target Engagement and Trustworthiness Detection in Real-life Media”. Proceedings of the 28th ACM International Conference on Multimedia. Seattle, PA, USA: Association for Computing Machinery: 4769–4770. arXiv:2004.14858. doi:10.1145/3394171.3421901. S2CID222278714.
مجموعه داده ای برای تجزیه و تحلیل احساسات با استفاده از سیگنال های eeg ، فیزیولوژیکی و ویدئویی
خلاصه
ما یک مجموعه داده چند حالته برای تجزیه و تحلیل حالات عاطفی انسان ارائه می دهیم. الکتروانسفالوگرام (EEG) و سیگنال های فیزیولوژیکی محیطی 32 شرکت کننده در حالی که هر یک از آنها 40 قطعه یک دقیقه ای از ویدیو های موسیقی را تماشا می کردند ، ضبط شد. شرکت کنندگان به هر ویدئو از نظر سطح تحریک ، قدرت ، مانند / دوست نداشتن ، سلطه و آشنایی امتیاز دادند. برای 22 نفر از 32 شرکت کننده ، فیلم چهره جلویی نیز ضبط شده است. یک روش جدید برای انتخاب محرکها ، با استفاده از بازیابی توسط برچسبهای احساسی از وب سایت last.fm ، تشخیص برجسته ویدیو و یک ابزار ارزیابی آنلاین.
این مجموعه داده در دسترس عموم قرار گرفته است و ما سایر محققان را به استفاده از آن برای آزمایش روش های برآورد حالت عاطفی خود تشویق می کنیم. این مجموعه ابتدا در مقاله زیر ارائه شد:
اگر به استفاده از این مجموعه داده علاقه دارید ، باید EULA (توافق نامه مجوز کاربر نهایی) را چاپ ، امضا و اسکن کرده و از طریق فرم درخواست مجموعه داده بارگذاری کنید. سپس یک نام کاربری و رمز عبور برای بارگیری داده ها به شما ارائه خواهیم داد. لطفا برای اطلاعات بیشتر به صفحه بارگیری بروید .
تجزیه و تحلیل حساسیت CNN های یک لایه را برای بررسی تأثیر م componentsلفه های معماری بر عملکرد مدل و تشخیص تفاوت بین تصمیمات مهم و نسبتاً بی نتیجه برای طبقه بندی جملات انجام دهید.
1. یک شبکه توجه سلسله مراتبی برای طبقه بندی اسناد پیشنهاد دهید. 2. دارای ساختار سلسله مراتبی است که نمایانگر ساختار سلسله مراتبی اسناد است. 3. دارای دو سطح مکانیسم توجه است که در کلمه و در سطح جمله به کار می رود ، و آن را قادر می سازد تا هنگام ساخت نمایندگی سند متفاوت با محتوای کم اهمیت بیشتری حضور یابد. 4. در مورد تفسیر کلمات و جمله های توجه آموخته شده نامشخص است.
1. مدل جهانی زبان را برای تنظیم دقیق (ULMFiT) ، یک روش یادگیری انتقال م thatثر که می تواند برای هر کاری در NLP اعمال شود ، پیشنهاد دهید و فنونی را تنظیم کنید که برای تنظیم دقیق یک مدل کلیدی است. 2. به طور قابل توجهی از عملکرد پیشرفته شش کار طبقه بندی متن بهتر عمل می کند